前言
球谐函数被游戏普遍运用,由于能通过一组基函数和系数去还原颜色信息,非常适合环境光漫反射去使用。unity中,我们我们通过SampleSH9函数去获得球谐光照的结果。那么,球谐光照是如何实现的,如何通过任意的Cubemap去还原球谐,本文将会带你快速入门。
当然,球谐系数不仅仅可以用在环境光照,也可以用在其他方面,本文末尾会有相关的一些引申。
同样,作为快速入门系列,并不会涉及球谐函数的具体推导【过于复杂,并且需要有非常好的基础,具体可以参考chopper大佬的文章:球谐光照——球谐函数 - 知乎
(zhihu.com)】,相关推导过程这里只会一笔带过【问就是不会】
球谐函数 Spherical harmonics
球谐函数是球坐标下的拉普拉斯方程的其中一个方程的解。球谐函数在球面S具有正交性,同时也具有完备性。可以对球面上的函数,利用球谐对其进行级数展开。类似于傅里叶级数展开,可以用N个函数的线性组合去逼近原函数的曲线【盗一张图: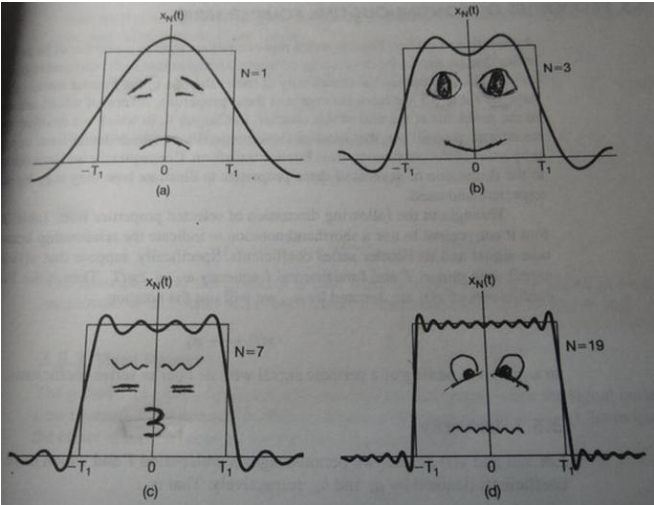 ,如果看了这篇文章你还不懂傅里叶变换,那就过来掐死我吧
- 知乎 (zhihu.com)】
,如果看了这篇文章你还不懂傅里叶变换,那就过来掐死我吧
- 知乎 (zhihu.com)】
球谐函数可以如下表示:
这里yi就是球谐基函数,ci就是球谐系数,放到环境光这一个话题内,f就是颜色。ci可以通过正交基函数获得
通常,我们为了节省计算量【主要是由于如果SH用于计算环境光的漫反射,漫反射比较低频不需要非常精确】,会用蒙特卡罗积分去近似
我们可以这样理解:原本的信息,可以通过球谐函数的几组基函数,去趋近,达到用更少的数据获得更加还原的表现。本质上可以理解为信息的压缩
举一个例子:假如一组基函数是 Y1 Y2 Y3 ,对应的系数为 C1 C2
C3,我们就能通过只存储C1 C2 C3,去还原先前的信号
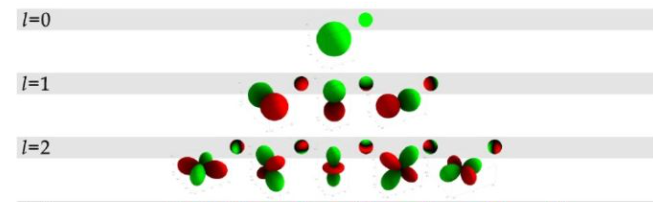
在球谐光照中,一我们一般用3阶一共9个系数,存储的是RGB信息,所以是9*3=27个系数,下图是前三阶的球谐函数的可视化
上文由于是个人的精简总结,可能存在一些词不达意的地方。对SH基础有兴趣的强烈推荐一下浦夜的球谐函数介绍【球谐函数介绍(Spherical
Harmonics) - 知乎
(zhihu.com)】,这篇文章基本不涉及推导,非常多形象的比喻和例子,非常容易去了解球谐函数是什么。更深入可以去看这篇:球谐光照与PRT学习笔记(三):球谐函数
- 知乎 (zhihu.com)
为什么环境光漫反射适合球谐
我们回顾一下环境光的渲染方程,一个点在半球范围内的irradiance为 最终的颜色渲染方程为(f为对应的BRDF): 也就是说,需要计算漫反射,我们首先需要获得irradianceMap
LearnOpenGL在PBR的IBL章节里,有这一张图,从Cubemap到IrradianceMap:
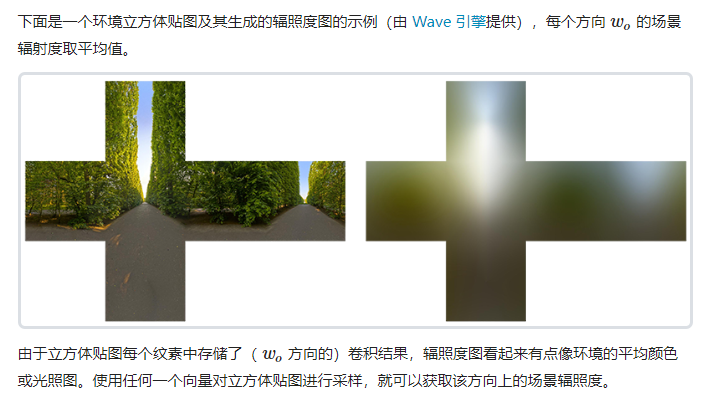
但是,假如我们真的在Shader里去对Cubemap对应的raddiance去做各个方向的卷积操作,显然是性能压力非常大的。在实时渲染中,我们可以通过直接从cubeMap生成IrradianceMap,然后在Shader里采样,去代替这个在shader里多次采样再卷积的操作。用一次采样代替多次采样卷积。
也就是说,IrradianceMap如果我们能生成了,那就意味着我们可以用一次采样一张贴图去代替对于Cubemap多次采样再卷积的操作。
那么,可以更加省吗?答案是可以的,前面说道的球谐就是这样非常适合用更少的数据去还原这种低频的数据
如果使用球谐系数,我们甚至可以不需要采样,只需要9个系数和对应的球谐基函数相乘求和,就能还原出irradiance
也就是说,球谐函数其实和采样贴图都是一个用(为了在Shader里获得irradianceMap)
如何从Cubemap利用SH重建光照
下文会具体阐述,如何利用computeShader【如果在Cpu处理相对的处理时间会比较长,computeShader的并行能力非常适合做这个事情】从Cubemap生成IrradianceMap,再生成SH系数在Shader里还原。
整体思路是这样的,我们需要先对记录radiance信息的Cubemap做球面卷积,获得irradiancemap,再通过上分提及的系数C的求法,对基函数*颜色做一次蒙特卡洛积分获得系数
首先,我们需要为computeShader去创建一个irradiancemap的RT【如果Dimension是Cube,似乎computeshader并不能做到读写,所以就把Cubemap的6个面存到tex2dArray里】,同时irradiancemap比较低频,我们不需要多大的分辨率,128就足够了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| //生成IrradianceMap
RenderTextureDescriptor desc = new RenderTextureDescriptor();
//IrradianceMap比较低频,小分辨率够用 这里存CubeMap的6个面【主要ComputeShader需要用到normalDir,需要通过面和UV去生成】
desc.width = 128;
desc.height = 128;
desc.autoGenerateMips = false;
desc.depthBufferBits = 0;
desc.colorFormat = RenderTextureFormat.ARGBFloat;
desc.dimension = TextureDimension.Tex2DArray;
desc.enableRandomWrite = true;
desc.msaaSamples = 1;
desc.sRGB = true;
desc.useMipMap = false;
desc.volumeDepth = 6;
desc.mipCount = -1;
RenderTexture rt_Irradiance = new RenderTexture(desc);
rt_Irradiance.Create();
|
然后我们需要对每个像素,做一次半球的卷积操作,我们可以通过UV和Cubemap的面的朝向,获得方向,我这里最终结果除了Pi是因为漫反射的BRDF为
我们可以在IrradianceMap阶段就算完,减少Shader的计算量
BruteForce获得IrrdianceMap的方案如下:

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| float3 Gen_Irradiance(uint3 id)
{
//ref:https://www.cnblogs.com/idovelemon/p/12150757.html BruteForce 方法
float3 irrandiance =0;
//RfromUV(uint face, float u, float v)
float2 uv=float2(id.xy)/(_IrradianceMapSize-1); //像素映射到UV的0-1范围
float3 normal=RfromUV(id.z/*face*/,uv.x,uv.y);
//拿到每个像素的Irradiance
float total_SolidAngle=0;
for(float f=0;f<6;++f)//遍历face
{
for(float i=0 ;i<_CubeMapSize;++i)
{
for(float j=0 ;j<_CubeMapSize;++j)
{
float2 uv_dir=float2(i,j)/(_CubeMapSize-1); //RadianceMap各个方向对应的UV
half3 w=RfromUV(f,uv_dir.x,uv_dir.y);
//Radiance
float3 L= _CubeMapRadiance.SampleLevel(sampler_LinearClamp,w,0).rgb;
float dw=DifferentialSolidAngle(_CubeMapSize,uv_dir);
total_SolidAngle+=dw;
irrandiance+=L*saturate(dot(normal,w))*dw;
}
}
}
return irrandiance*4/total_SolidAngle; //4PI/SOLIDANGLE/PI
}
[numthreads(8,8,6)]
void irradianceGenerator(uint3 id : SV_DispatchThreadID)
{
//IrradianceMap[id.xy] = float4(1,1,1,0);
float3 irrdiance=Gen_Irradiance(id);
IrradianceMap[id.xyz] = float4(irrdiance.rgb*1.5,1.0);
// float2 uv=float2(id.xy)/(_IrradianceMapSize-1); //像素映射到UV的0-1范围
// float3 normal=RfromUV(id.z/*face*/,uv.x,uv.y);
// IrradianceMap[id.xyz] = float4(pow(_CubeMapRadiance.SampleLevel(sampler_LinearClamp,normal,6).rgb ,0.45) ,1.0);
}
|
我们同样可以通过ComputeShader输出看看irradianceMap生成的结果作为Debug,老样子按照Cubemap的面存储6个RT,最后合到一张图内手动转Cube:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| if (_enableDebug)
{
int kernel_Debug = cs.FindKernel("debug");
RenderTextureDescriptor desc2d = new RenderTextureDescriptor();
//IrradianceMap比较低频,小分辨率够用 这里存CubeMap的6个面【主要ComputeShader需要用到normalDir,需要通过面和UV去生成】
desc2d.width = 128;
desc2d.height = 128;
desc2d.autoGenerateMips = false;
desc2d.depthBufferBits = 0;
desc2d.colorFormat = RenderTextureFormat.ARGBFloat;
desc2d.dimension = TextureDimension.Tex2D;
desc2d.enableRandomWrite = true;
desc2d.msaaSamples = 1;
desc2d.sRGB = true;
desc2d.useMipMap = false;
desc2d.volumeDepth = 1;
desc2d.mipCount = -1;
//RenderTexture irradiance2d = new RenderTexture(128, 128, 0, RenderTextureFormat.ARGBFloat, -1);
RenderTexture irradiance2d = new RenderTexture(desc2d);
irradiance2d.enableRandomWrite = true;
cs.SetTexture(kernel_Debug, "IrradianceMap", rt_Irradiance);
Texture2D[] irrArr = new Texture2D[6];
for (int i = 0; i < 6; i++)
{
irrArr[i] = new Texture2D(128, 128, TextureFormat.RGBAFloat, -1, true);
}
RenderTexture active = RenderTexture.active;
for (int i = 0; i < 6; ++i)
{
cs.SetTexture(kernel_Debug, "IrradianceMap_2D", irradiance2d);
cs.SetInt("_index", i);
cs.Dispatch(kernel_Debug, Mathf.CeilToInt(128 / 8.0f), Mathf.CeilToInt(128 / 8.0f), 1);
RenderTexture.active = irradiance2d;
irrArr[i].ReadPixels(new Rect(0, 0, 128, 128), 0, 0);
}
|
1
2
3
4
5
6
7
8
9
10
11
| [numthreads(8,8,6)]
void debug(uint3 id : SV_DispatchThreadID)
{
IrradianceMap_2D[id.xy]=pow(IrradianceMap[uint3(id.xy,_index)],0.45);
}
|
结果是这样的:
这是生成的IrradianceMap

这是原图:

到这里,所谓的漫反射信息已经有了,也就是生成的IrradianceMap,接下来我们就需要把这个128的贴图利用球谐,压缩成9个RGB系数,27个float值
这里生成SH系数,由于ComputeShader的并行特性,需要用到GroupMemoryBarrierWithGroupSync()来打断并行,
其中由于数组超过最大大小了,所以我只能让每个系数按照index走一次ComputeShader
SH系数的这部分我参考的Zilch的实现,在computeShader内我们计算的每个线程组的求和大体如下,是一个不断二分的过程:
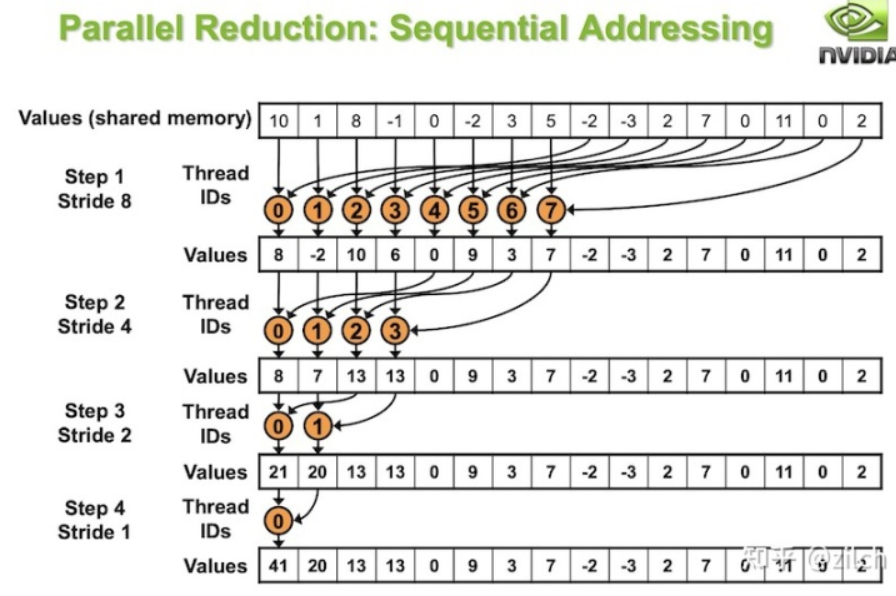
同时,由于这样的求和只是一个线程组内的求和,我们申请的线程组只是8x8x6大小【8x8个像素,6个Cube的face】事实上存在128/8
* 128/8个线程组,
我们需要把所有线程组的结果再回读到CPU,在CPU端做最后的求和操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| ComputeBuffer shcBuffer = new ComputeBuffer(128 / 8 * 128 / 8 * 9, 16);
int kernel_ComputeSh = cs.FindKernel("SHCoefGenerator");
cs.SetTexture(kernel_ComputeSh, "IrradianceMap", rt_Irradiance);
cs.SetBuffer(kernel_ComputeSh,"shcBuffer", shcBuffer);
for (int i = 0; i < 9; ++i)
{
cs.SetInt("_SHCindex", i);
cs.Dispatch(kernel_ComputeSh, rt_Irradiance.width / 8, rt_Irradiance.height / 8, 1);
}
AsyncGPUReadback.Request(shcBuffer, (req) =>
{
var groupShc = req.GetData<Vector4>();
var count = groupShc.Length / 9;
for (var i = 0; i < count; i++)
{
for (var offset = 0; offset < 9; offset++)
{
shc[offset] += groupShc[i * 9 + offset];
}
}
for (int i = 0; i < 9; ++i)
{
Debug.Log("SHC" + i + ":" + shc[i]);
}
shcBuffer.Release();
});
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
| void GroupADD(uint shIndex,uint shIndex2)
{
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
shcGroup[shIndex] += shcGroup[shIndex2];
}
void GenSHCoefs(uint3 id,uint groupIndex,uint3 groupID)
{
float4 irrdiance=IrradianceMap.Load(uint4(id.x,id.y,id.z,0));
irrdiance.w=0;
float N=_IrradianceMapSize.x*_IrradianceMapSize.x*6;
float A=12.5663706/N;
float2 uv=id.xy/(_IrradianceMapSize-1);
A=DifferentialSolidAngle(128,uv);
float3 dir=RfromUV(id.z,uv.x,uv.y);
switch(_SHCindex)
{
case 0:
shcGroup[groupIndex ] = irrdiance * Y0(dir) * A;
break;
case 1:
shcGroup[groupIndex ] = irrdiance * Y1(dir) * A;
break;
case 2:
shcGroup[groupIndex ] = irrdiance * Y2(dir) * A;
break;
case 3:
shcGroup[groupIndex ] = irrdiance * Y3(dir) * A;
break;
case 4:
shcGroup[groupIndex ] = irrdiance * Y4(dir) * A;
break;
case 5:
shcGroup[groupIndex ] = irrdiance * Y5(dir) * A;
break;
case 6:
shcGroup[groupIndex ] = irrdiance * Y6(dir) * A;
break;
case 7:
shcGroup[groupIndex ] = irrdiance * Y7(dir) * A;
break;
case 8:
shcGroup[groupIndex ] = irrdiance * Y8(dir) * A;
break;
}
// //https://github.com/pieroaccardi/Unity_SphericalHarmonics_Tools/blob/master/Assets/SH/Resources/Shaders/Reduce_Uniform.compute
// GroupMemoryBarrierWithGroupSync();
// uint flatGI = groupIndex % 64;
// if (flatGI < 32)
// GroupADD(groupIndex,groupIndex+32);
// GroupMemoryBarrierWithGroupSync();
// if (flatGI < 16)
// GroupADD(groupIndex,groupIndex+16);
// GroupMemoryBarrierWithGroupSync();
// if (flatGI < 8)
// GroupADD(groupIndex,groupIndex+8);
// GroupMemoryBarrierWithGroupSync();
// if (flatGI < 4)
// GroupADD(groupIndex,groupIndex+4);
// GroupMemoryBarrierWithGroupSync();
// if (flatGI < 2)
// GroupADD(groupIndex,groupIndex+2);
// GroupMemoryBarrierWithGroupSync();
// if (flatGI < 1)
// GroupADD(groupIndex,groupIndex+1);
// GroupMemoryBarrierWithGroupSync();
// if (groupIndex==0) //把6个面的求和结果相加
// {
// uint index =( groupID.x +groupID.y * 16 )*9;
// shcBuffer[index ] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+1] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+2] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+3] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+4] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+5] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+6] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+7] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// shcBuffer[index+8] = shcGroup[0]+ shcGroup[64] +shcGroup[128]+ shcGroup[192]+ shcGroup[256]+ shcGroup[320];
// }
GroupMemoryBarrierWithGroupSync();
for(uint k=64*6>>1;k>0;k>>=1)
{
if(groupIndex<k)
{
uint shIndex = groupIndex ;
uint shIndex2 = (groupIndex + k) ;
{
shcGroup[shIndex] += shcGroup[shIndex2];
}
}
GroupMemoryBarrierWithGroupSync();
}
if(groupIndex == 0){
uint groupCountX = _IrradianceMapSize.x / 8;
uint index = (groupID.y * groupCountX + groupID.x) * 9;
{
shcBuffer[index+_SHCindex] = shcGroup[0];
}
}
}
//ref : https://github.com/wlgys8/SHLearn/blob/master/Assets/SHLightLearn/Shaders/Resources/SH9ProjectFromCubeMap.compute
[numthreads(8,8,6)]
void SHCoefGenerator(uint3 groupID : SV_GroupID,uint3 id : SV_DispatchThreadID,uint groupIndex : SV_GroupIndex)
{
GenSHCoefs(id,groupIndex,groupID);
}
|
最后我们只需要把生成的系数在Shader里还原就行,结果如下,和Unity自带的SH效果是一致的。
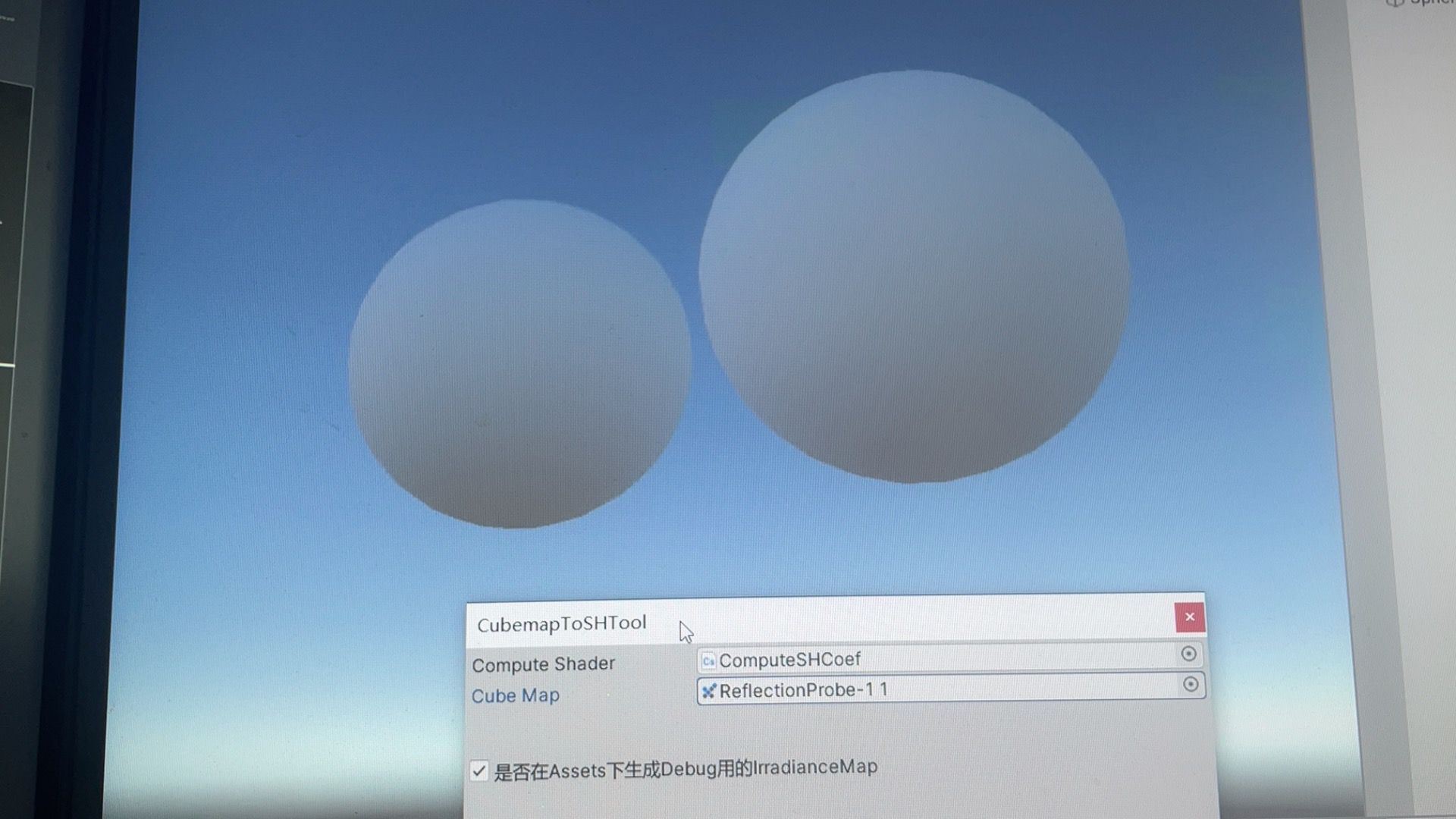
引申
球谐系数看完上文,就知道,他并不一定用于存储环境的光照信息,可以用来还原其他的信息。举个例子,体渲染渲染透射中,由于我们不了解对应viewDir的光学深度,需要raymarching去获得。如果是存储深度图事实上并不合理,和视角无关了,而我们可以利用球谐函数,记录不同视角的深度数据,去近似原来的光学深度(常用于规则形状的玉石之类的渲染)
举个例子,永劫无间的玉石渲染《永劫无间》透光材质的渲染:器物之美,终归于心
- 知乎 (zhihu.com)不过他们是在houdini里去烘焙的SH
这里有一套Unity的SH透射GitHub
- pieroaccardi/Unity_SphericalHarmonics_Translucency: Translucency
effect for Unity using the Spherical Harmonics basis
